What AI blood test interpretation actually means
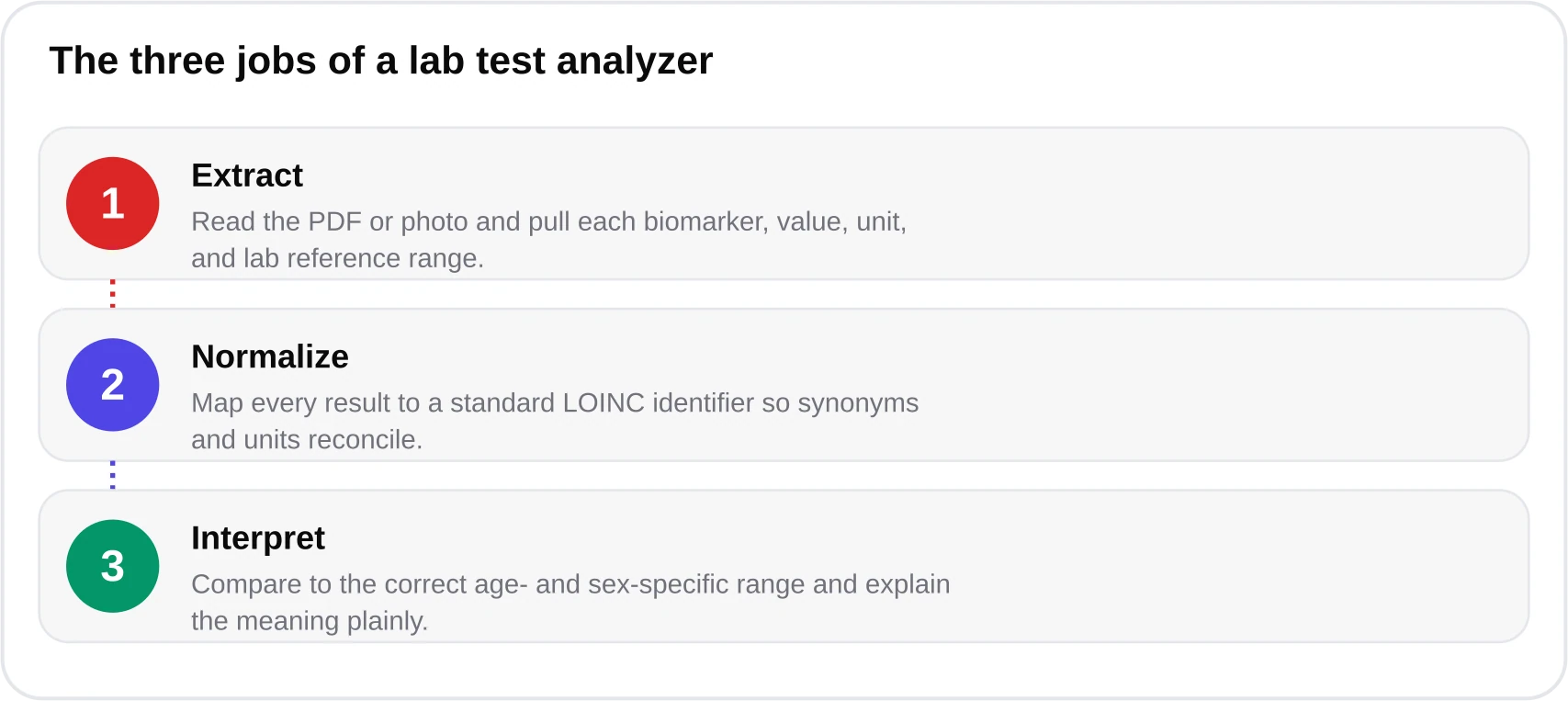
When people say AI blood test interpretation, they usually mean one of two very different things. The first is explanation: asking software what a biomarker like ALT, ferritin, or TSH is and what it does. The second is interpretation: taking your specific numbers, comparing each one to the correct reference interval for your age and sex, applying clinical logic across related markers, and telling you what actually falls outside range and how confident that flag is. General chatbots are excellent at the first task. The second task is where a purpose-built pipeline earns its keep.
The distinction matters because a lab report is not prose — it is structured data with units, reference ranges, collection context, and interdependencies. A hemoglobin of 11.8 g/dL is 'low' for an adult man and squarely 'normal' for a pregnant woman in the third trimester. Interpreting it correctly requires knowing who you are, not just what the number is. That is the core reason we built the analyzer at blood-test.life as a specialized system rather than a thin wrapper around a general model. Our engine is powered by the Kantesti AI infrastructure, but the clinical guardrails around it are what make a number trustworthy.

Interpretation also has to be reproducible. If you paste the same panel twice into a general chatbot, you can get two subtly different readings because the model samples probabilistically. A clinical result should not change because you asked on a Tuesday. Reproducibility is a design property you have to engineer in — through deterministic rules, fixed reference tables, and versioned logic — not something you get for free from a large language model.
Where ChatGPT genuinely shines
Let us be fair to large language models, because the honest case is more useful than a strawman. Modern LLMs are genuinely superb at explanation and empathy. Ask ChatGPT what C-reactive protein measures, why your doctor ordered a lipid panel, or how to phrase a question for your next appointment, and you will usually get a clear, patient, well-organized answer. For plain-language education, they are a real advance over a wall of medical jargon, and we say so plainly in our guide to reading results with AI.
LLMs are also strong at synthesis — pulling together the general significance of a pattern, suggesting reasonable lifestyle questions, and translating between languages. The problem is not that they are bad at language. It is that a blood report is a data-integrity and safety problem wearing the costume of a language problem. The moment interpretation depends on a precise threshold, a unit conversion, or a partitioned reference range, the general model's fluency becomes a liability: it will state a wrong number with exactly the same confident tone it uses for a right one.

A language model that has never been evaluated on labs will still answer every lab question. Fluency is not the same as being right, and in medicine the gap between the two is where harm lives.
— Dr. Linda Wei, PhD, Head of AI Research, blood-test.life
Seven ways raw ChatGPT gets labs wrong
Across thousands of side-by-side comparisons, the failure modes of a general chatbot on a real lab report cluster into seven recurring categories. None of these mean LLMs are useless — they mean a raw LLM is the wrong tool for the interpretation step specifically.
- No age/sex/pregnancy partitioning. Reference intervals differ by age and sex — the CALIPER and NORIP studies exist precisely because pediatric and adult ranges diverge sharply. A general chatbot typically applies one generic 'normal' band and misflags children, older adults, and pregnant patients.
- Unit confusion. Glucose in mg/dL versus mmol/L, or ferritin scales, are trivially swapped. A misplaced conversion turns a normal value into a false alarm or, worse, hides a real one.
- Hallucinated references and thresholds. LLMs can invent citations and cutoffs that sound authoritative. Documented cases of fabricated medical references are exactly why we never let the model free-type a threshold.
- No deterministic clinical-rules guardrail. Whether HbA1c ≥6.5% is diabetes-range should never be a probabilistic guess; it is a fixed rule per ADA Standards of Care.
- No named medical review. There is no physician standing behind a raw chatbot's output, and no accountable name attached to a flag.
- No validation number. A general model cannot tell you its extraction accuracy or physician-agreement rate on labs, because no such study exists for that use.
- No trend tracking or privacy guarantee. It cannot chart your ferritin over three years, and pasted health data may be retained or used to improve the service unless you have opted out.


The pattern is consistent: fluency stays high across all four bars, but correctness improves only when you constrain the model. That constraint is the entire point of a specialized system. We cover the mechanics of how the model and rules cooperate in our explainer on how machine learning reads labs.

A worked example: same result, two answers
Consider a common scenario. A 68-year-old woman uploads a complete blood count. Her hemoglobin is 11.6 g/dL. A general chatbot applying a single adult-male-leaning 'normal' of roughly 13.5–17.5 g/dL will call this markedly low and may spin an alarming narrative. But the correct sex-partitioned adult-female interval sits near 12.0–15.5 g/dL, so 11.6 is only mildly below range — a finding that warrants a look at iron studies, not a panic. The number did not change; the reference frame did.

This is not a hypothetical edge case; it is the median lab report. Roughly 5% of perfectly healthy people fall outside any given reference range by definition, because reference intervals are built as the central 95% of a healthy population. Order twenty markers and, statistically, one will read 'abnormal' in a healthy person. A tool without proper ranges and cross-marker logic turns that statistical noise into anxiety. A specialized analyzer contextualizes it — which is exactly what our CBC explainer and iron-deficiency guide are built to do.

Inside a guardrailed pipeline
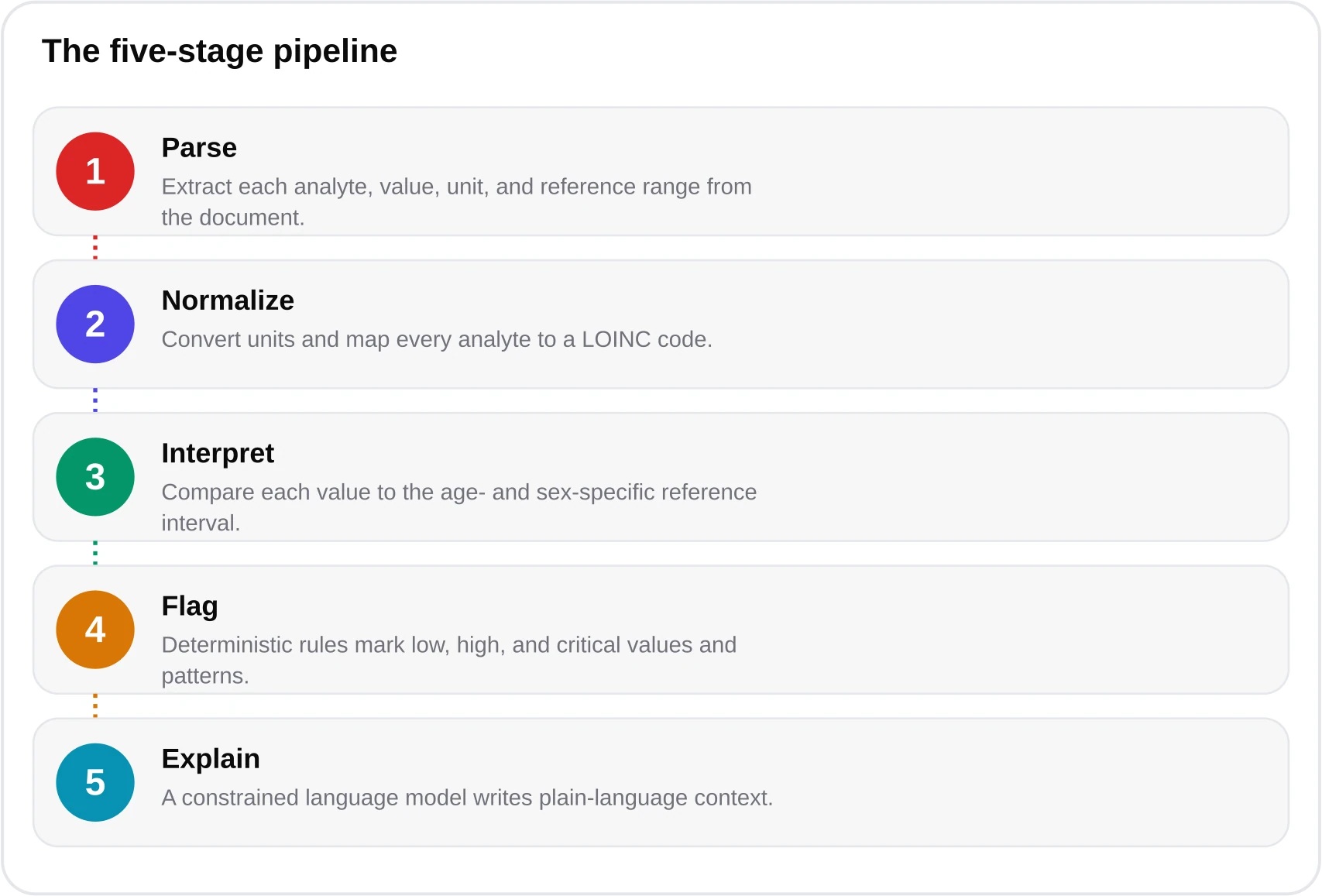
So what does a specialized system do that a chat window does not? It runs your report through a fixed sequence of stages, each with its own safeguards, rather than handing everything to one probabilistic model. The architecture is the product. Our engine combines health-llm-v4.7 for language with a deterministic clinical-rules engine for every threshold, mapped through LOINC and partitioned with CALIPER and NORIP reference data. You can read the full breakdown in our methodology.

The critical design choice is that the language model never decides a threshold. Whether your fasting HbA1c of 5.9% lands in the prediabetes band (5.7–6.4%) or your LDL clears the general-population target of <100 mg/dL, or the tighter <70 mg/dL for high-risk patients and <55 mg/dL for established cardiovascular disease under AHA/ACC and ESC guidance, is decided by code, not by generation. The model's job is to explain the rule's output in human language — never to guess the rule. This is the single most important difference between our analyzer and a raw chatgpt blood test paste. For a deeper technical treatment, Kantesti — the AI engine behind blood-test.life — publishes an excellent breakdown of blood test interpretation with AI that we recommend as further reading.


Privacy, training, and trust
There is a quieter difference that matters as much as accuracy: what happens to your data. When you paste a lab report into a general consumer chatbot, that text may be retained and, depending on your settings, used to improve the service. Health data is uniquely sensitive, and 'depending on your settings' is not a reassurance most patients should accept by default. Our commitment is explicit and structural: uploaded files are deleted after your report is delivered, and we never train models on your data. The platform is HIPAA-aligned and GDPR/CCPA-compliant.

Trust is also about accountability. Our flag logic is reviewed by named clinicians — Dr. James Carter, MD (Internal Medicine, Johns Hopkins), Dr. Amelia Rodriguez, MD (Cardiology, UCSF), Dr. Ahmed Khalil, MD (Endocrinology, Mayo), and Dr. Sophie Laurent, MD MPH (Hematology, Penn) — people whose professional reputations are attached to the output. A general chatbot offers fluent text with no one standing behind it. That difference is invisible until the moment a flag is wrong, and then it is the only thing that matters.
An honest limitation
No AI here is a medical device, and nothing in a report is a diagnosis. Reference ranges vary between labs, and roughly 5% of healthy people fall outside any range by design. If you have symptoms, an urgent value, or a flagged result, see a licensed clinician — the analyzer is a fast, validated way to understand your numbers, not a replacement for care.
How to choose — and how to use both
This is not really a fight to the death between two technologies. The smartest approach uses each for what it is good at. Use a general chatbot for open-ended education: what a marker means, how to prepare for a test, how to phrase questions for your doctor. Use a specialized analyzer for the actual interpretation of your numbers, where partitioned ranges, deterministic rules, validation, and privacy are non-negotiable. Our 2026 buyer's guide walks through the criteria in more detail, and Kantesti's practical primer on how to read blood test results is a strong companion read.
If you want a concrete checklist before trusting any AI with a report, ask: Does it publish a validation number on real reports? Does it use age- and sex-specific ranges? Does it apply fixed clinical rules rather than generated thresholds? Is there named physician review? Does it delete your files and refuse to train on them? A yes to all five puts you in clinical-grade territory; a no to any of them means you are getting explanation, not interpretation. You can see the difference for yourself in our sample report or by running your own labs through the free analyzer.

The analyzer is free during the 2026 public beta, with credit packs planned afterward at 60% off — 5 credits for $24.90, 20 for $69.90, and 50 for $149.90. It handles 120+ biomarkers, returns results in under 60 seconds, and supports reports in 75+ languages with native medical QA in 15. Explore what it flags across panels in our biomarker library, or start with a focused guide like the lipid panel, thyroid panel, or HbA1c explainer.
The bottom line
A general chatbot is a brilliant explainer and a risky interpreter. It will tell you, fluently and confidently, what a marker means — and it will just as fluently apply the wrong reference range, swap a unit, or state a threshold it never verified. AI blood test interpretation done responsibly is not one model answering questions; it is a pipeline of extraction, normalization, deterministic clinical rules, and named physician review, measured against real reports and honest about its limits. That is the difference between an answer that sounds right and a result you can act on. Use the chatbot to learn. Use a specialized, validated analyzer — like ours, powered by the Kantesti AI engine — to interpret.
Frequently asked questions
Can I just paste my blood test into ChatGPT?
You can, and it will give you a fluent explanation of what each marker means. The risk is in interpretation: a general chatbot often applies a single generic reference range rather than age-, sex-, and pregnancy-specific intervals, can swap units, and may state thresholds it never verified. For understanding what a marker is, it's useful; for deciding what's actually abnormal in your numbers, a validated analyzer with a deterministic rules engine is safer.
Is AI blood test interpretation a diagnosis?
No. Neither a general chatbot nor a specialized analyzer provides a diagnosis or is a medical device. These tools flag values against reference ranges and explain their significance. Reference ranges vary between labs, and about 5% of healthy people fall outside any given range by design. If you have symptoms, an urgent value, or a flagged result, see a licensed clinician.
Why does age and sex matter so much for reference ranges?
Reference intervals are built from healthy populations and differ substantially by age and sex — which is why the CALIPER and NORIP studies exist to partition them. The same hemoglobin, ferritin, or creatinine value can be normal for one group and abnormal for another. Applying one generic range, as many general chatbots do, produces false alarms and missed findings.
How does a specialized analyzer avoid hallucinated thresholds?
It separates language from logic. The language model explains results in plain terms, but every threshold — HbA1c ≥6.5% for diabetes range, LDL targets, TSH bounds near 0.4–4.0 mIU/L — is applied by a deterministic clinical-rules engine using fixed reference tables mapped through LOINC. The model never free-types a cutoff or a citation, which is how blood-test.life reaches 97.4% flag agreement with physicians.
What happens to my data with each option?
With a consumer chatbot, pasted text may be retained and, depending on your settings, used to improve the service. blood-test.life deletes uploaded files after your report is delivered and never trains models on your data, and the platform is HIPAA-aligned and GDPR/CCPA-compliant. For sensitive health information, that structural guarantee is a meaningful difference.
Should I stop using ChatGPT for health questions entirely?
No — use each tool for its strength. General LLMs are excellent for open-ended education: what a test measures, how to prepare, how to phrase questions for your doctor. Use a specialized, validated analyzer for interpreting your actual numbers, where correct ranges, deterministic rules, physician review, and privacy matter. Combining both, and consulting a clinician when needed, is the best approach.
References & sources
- American Diabetes Association — Standards of Care in Diabetes (HbA1c criteria) — American Diabetes Association
- ACC/AHA Guideline on the Management of Blood Cholesterol (LDL targets) — American College of Cardiology
- ESC/EAS Guidelines for the Management of Dyslipidaemias — European Society of Cardiology
- CALIPER pediatric reference interval database — CALIPER Project (SickKids)
- NORIP Nordic Reference Interval Project — NORIP
- LOINC — Logical Observation Identifiers Names and Codes — Regenstrief Institute
- USPSTF Recommendations on screening — U.S. Preventive Services Task Force
- NHLBI — heart, lung, and blood reference information — National Heart, Lung, and Blood Institute
Medical disclaimer
This article is informational and educational only and is not a substitute for professional medical advice, diagnosis, or treatment. blood-test.life is not a medical device. Always consult your physician or a qualified health provider about your results. Read our full medical disclaimer.